- · 《中国科技信息》栏目设[05/29]
- · 《中国科技信息》数据库[05/29]
- · 《中国科技信息》收稿方[05/29]
- · 《中国科技信息》投稿方[05/29]
- · 《中国科技信息》征稿要[05/29]
- · 《中国科技信息》刊物宗[05/29]
一、稿件要求: 1、稿件内容应该是与某一计算机类具体产品紧密相关的新闻评论、购买体验、性能详析等文章。要求稿件论点中立,论述详实,能够对读者的购买起到指导作用。文章体裁不限,字数不限。 2、稿件建议采用纯文本格式(*.txt)。如果是文本文件,请注明插图位置。插图应清晰可辨,可保存为*.jpg、*.gif格式。如使用word等编辑的文本,建议不要将图片直接嵌在word文件中,而将插图另存,并注明插图位置。 3、如果用电子邮件投稿,最好压缩后发送。 4、请使用中文的标点符号。例如句号为。而不是.。 5、来稿请注明作者署名(真实姓名、笔名)、详细地址、邮编、联系电话、E-mail地址等,以便联系。 6、我们保留对稿件的增删权。 7、我们对有一稿多投、剽窃或抄袭行为者,将保留追究由此引起的法律、经济责任的权利。 二、投稿方式: 1、 请使用电子邮件方式投递稿件。 2、 编译的稿件,请注明出处并附带原文。 3、 请按稿件内容投递到相关编辑信箱 三、稿件著作权: 1、 投稿人保证其向我方所投之作品是其本人或与他人合作创作之成果,或对所投作品拥有合法的著作权,无第三人对其作品提出可成立之权利主张。 2、 投稿人保证向我方所投之稿件,尚未在任何媒体上发表。 3、 投稿人保证其作品不含有违反宪法、法律及损害社会公共利益之内容。 4、 投稿人向我方所投之作品不得同时向第三方投送,即不允许一稿多投。若投稿人有违反该款约定的行为,则我方有权不向投稿人支付报酬。但我方在收到投稿人所投作品10日内未作出采用通知的除外。 5、 投稿人授予我方享有作品专有使用权的方式包括但不限于:通过网络向公众传播、复制、摘编、表演、播放、展览、发行、摄制电影、电视、录像制品、录制录音制品、制作数字化制品、改编、翻译、注释、编辑,以及出版、许可其他媒体、网站及单位转载、摘编、播放、录制、翻译、注释、编辑、改编、摄制。 6、 投稿人委托我方声明,未经我方许可,任何网站、媒体、组织不得转载、摘编其作品。
中国科学技术大学副教授凌震华:基于表征解耦
作者:网站采编关键词:
摘要:雷锋网按:2020 年 8 月 7 日至 9 日,全球人工智能和机器人峰会(CCF-GAIR 2020)在深圳圆满举行。CCF-GAIR 2020 峰会由中国计算机学会(CCF)主办,雷锋网 (公众号:雷锋网) 、香港中文大学
雷锋网按:2020 年 8 月 7 日至 9 日,全球人工智能和机器人峰会(CCF-GAIR 2020)在深圳圆满举行。CCF-GAIR 2020 峰会由中国计算机学会(CCF)主办,雷锋网(公众号:雷锋网)、香港中文大学(深圳)联合承办,鹏城实验室、深圳市人工智能与机器人研究院协办。
从 2016 年的学产结合,2017 年的产业落地,2018 年的垂直细分,2019 年的人工智能 40 周年,峰会一直致力于打造国内人工智能和机器人领域规模最大、规格最高、跨界最广的学术、工业和投资平台。
8 月 8 日,在由深圳市人工智能学会、CCF 语音对话与听觉专业组协办的「前沿语音技术」专场上,中国科学技术大学电子工程与信息科学系副教授凌震华做了题为《基于表征解耦的非平行语料话者转换》的主题演讲。

凌震华副教授
凌震华副教授主要研究领域包括语音信号处理和自然语言处理。主持与参与多项国家自然科学基金、国家重点研发计划、安徽省语音专项等科研项目,已发表论文 100 余篇,论文累计被引 4000 余次,获国家科技进步奖二等奖和 IEEE 信号处理学会最佳青年作者论文奖。在 Blizzard Challenge 国际语音合成技术评测、Voice Conversion Challenge 国际语音转换技术评测等活动中多次获得测试指标第一名。
凌震华副教授现为电气电子工程师学会(IEEE)高级会员、中国计算机学会语音听觉与对话专业组委员、中国语言学会语音学分会学术委员会委员、全国人机语音通讯学术会议常设机构委员会委员。2014-2018 年曾任 IEEE/ACM TASLP 期刊副编辑。
在演讲中,凌震华副教授主要从语音转换所基于的语料类型出发,介绍了平行语料下实现语音转换的技术演变过程,并由此延伸到非平行语料下的语音转换。
其中在平行语料条件下,传统语音转换基于 GMM (高斯混合模型)实现。 2013 年后深度学习技术被引入语音转换任务,基于产生式训练的深度神经网络(Generative Trained Deep Neural Network, GTDNN)等模型相继被提出。不过无论是 GMM 还是 DNN,都面临源与目标语音帧对齐过程中出现的误差和不合理问题。近年来提出的序列到序列(seq2seq)语音转换方法可以有效改善这一问题,提升转换语音的自然度与相似度。
进一步,凌震华副教授谈到了在非平行语料条件下的语音转换,并表示这种场景普遍存在于实际应用中,也更有难度。基于非平行数据构造平行数据,以及分离语音中的文本与话者表征,是实现非平行语音转换的两条主要技术途径。
随后,凌震华副教授重点介绍了所提出的基于特征解耦的序列到序列语音转换方法,该方法在序列到序列建模框架下实现语音中文本相关内容和话者相关内容的分离,取得了优于传统逐帧处理方法的非平行语音转换质量,接近使用同等规模平行数据的序列到序列语音转换效果。
最后,凌震华副教授表示:
以下是凌震华副教授在 CCF-GAIR 2020?「前沿语音技术」专场中的演讲内容全文,雷锋网对其进行了不改变原意的编辑整理:
谢谢大家,今天我的报告题目是《基于表征解耦的非平行语料话者转换》。
之前各位老师已经介绍了语音技术领域的若干研究任务,如声纹识别、语音分离与增强等。话者转换是一种语音生成的任务,同时这个任务也和说话人的身份信息相关——之前介绍的声纹识别是从语音中识别身份,而话者转换是对语音中身份信息的控制和调整。

我的报告会围绕三个部分进行:
话者转换,又称语音转换,英文名为 Voice Conversion,指的是对源说话人的语音进行处理,使它听起来接近目标发音人,同时保持语音内容不变。

类比于计算机视觉领域的人脸替换工作,如 Deepfake 等,话者转换是对语音信号中的说话人身份信息进行处理,其应用领域包括娱乐化应用和个性化的语音合成等。同时,身份的匿名化、一致化也会使用到话者转换技术。
话者转换技术经过了从规则方法到统计建模的发展历程。现阶段的基于统计建模的话者转换方法,其转换过程通常包括三个主要步骤:
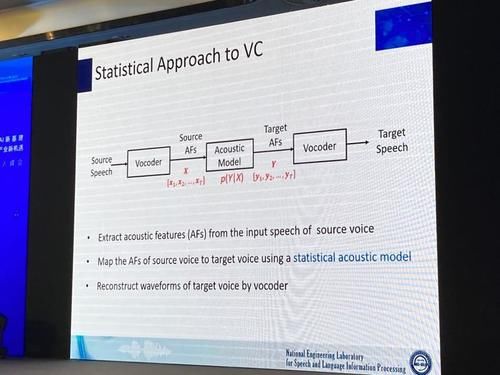
今天我们介绍的内容主要围绕中间的统计声学模型展开。在对于话者转换任务的背景介绍后,下面着重介绍平行语料和非平行语料条件话者转换任务的区别、主要方法,以及我们做过的一些相关工作。
文章来源:《中国科技信息》 网址: http://www.zgkjxx.cn/zonghexinwen/2020/0821/700.html
中国科技信息投稿 | 中国科技信息编辑部| 中国科技信息版面费 | 中国科技信息论文发表 | 中国科技信息最新目录
Copyright © 2018 《中国科技信息》杂志社 版权所有
投稿电话: 投稿邮箱: